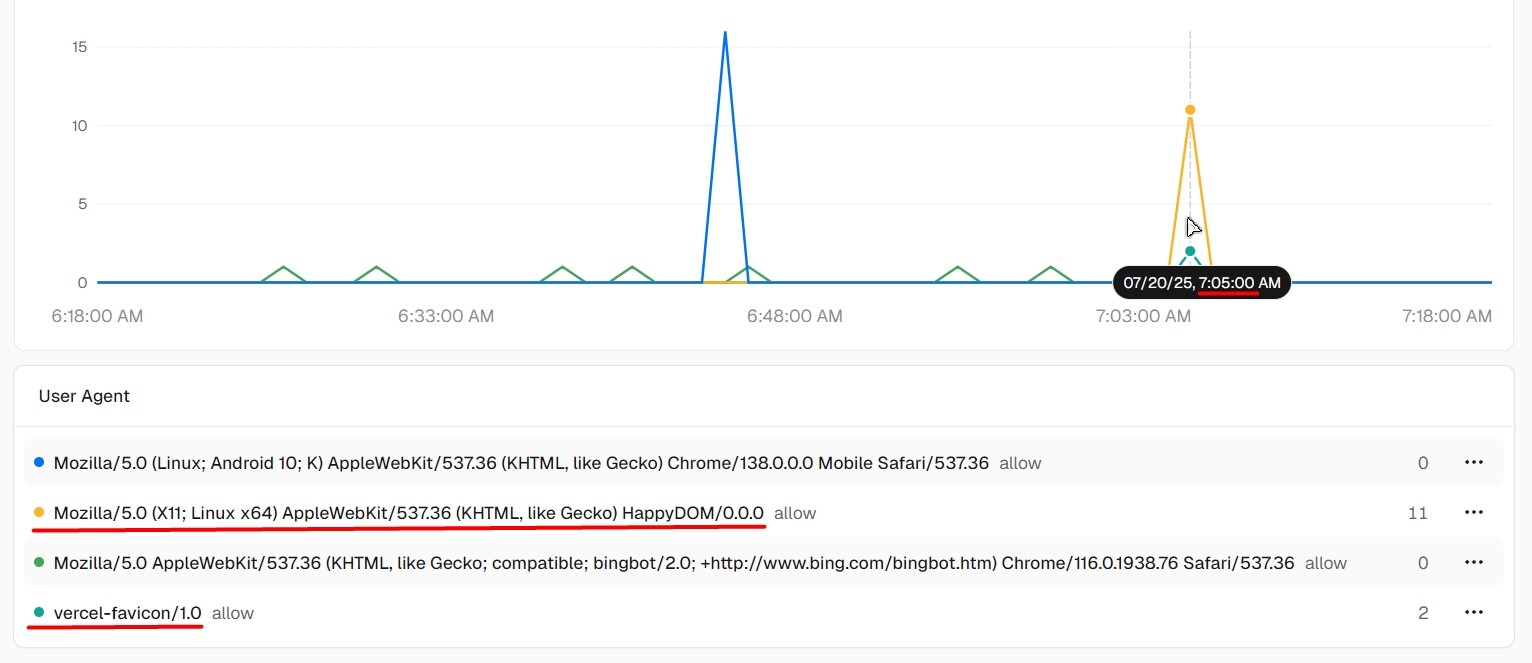
From what I understand, this is likely a headless DOM emulator (HappyDOM), used for scraping or automated testing.
Here’s what I’ve tried so far:
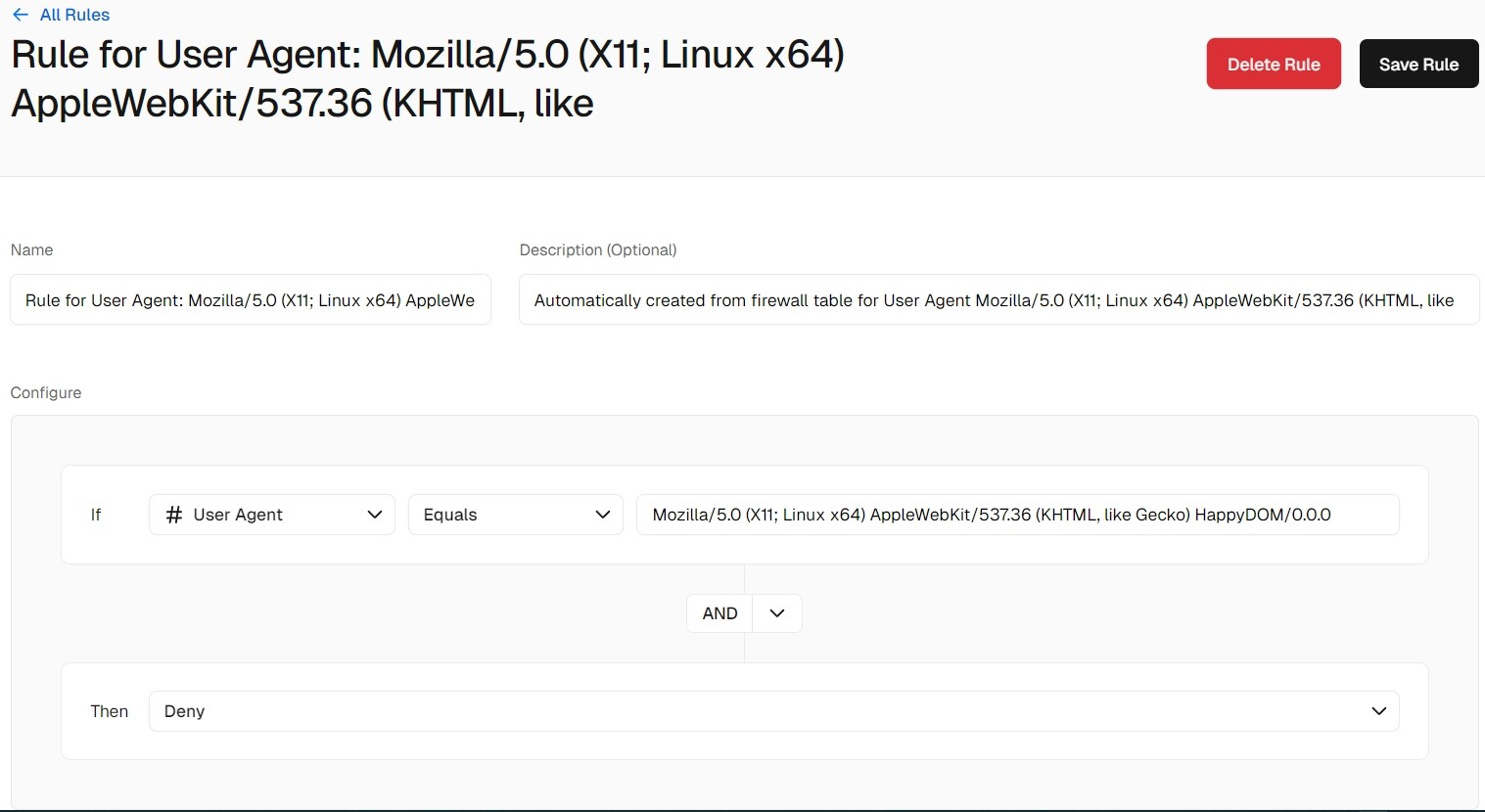
Created a Firewall rule that matches the User-Agent containing “HappyDOM” and set it to Deny – but I kept seeing new requests marked as Allowed.
Tried again with a different rule using a partial User-Agent match and Deny – no effect.
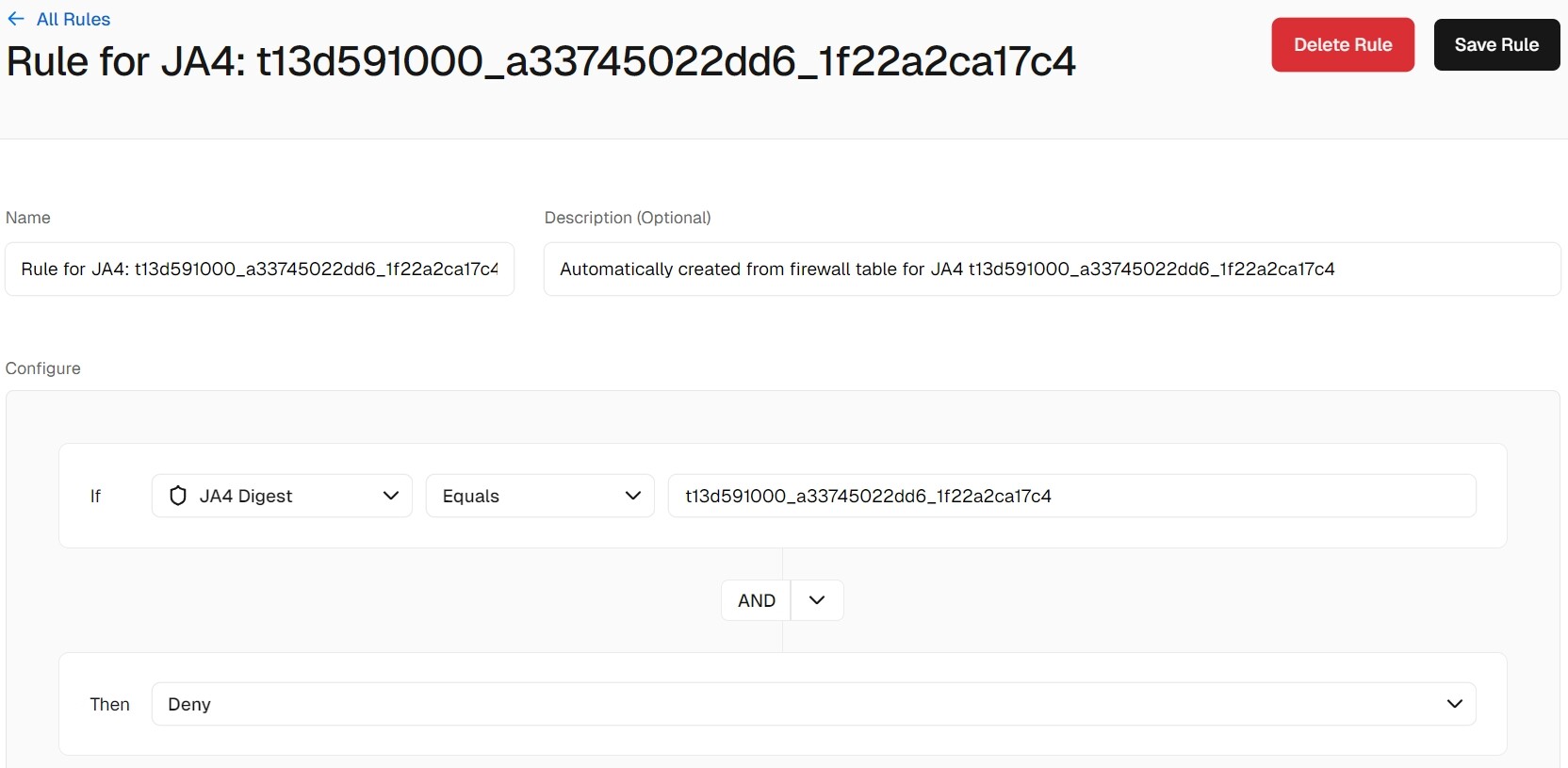
Most recently, I added a rule using JA4 Digest, matching the fingerprint of these requests and also set it to Deny – but I’m still seeing requests from the same User-Agent in my logs, with status “Allowed”.
So far, nothing seems to stop these requests from going through.
My questions:
Is there a reason why these requests still appear as Allowed even after being matched by Deny rules?
How can I ensure that these requests are fully denied and do not hit my site at all?
For context, my site is a mostly static Next.js project using SSG (static site generation). The only dynamic part is a single API route that handles search queries. I’m hosting it on Vercel (Hobby plan) with a custom domain. The site hasn’t been submitted to Google or any search engines, so I wasn’t expecting any crawler or bot activity at this stage. That’s why these repeated HappyDOM requests are concerning.
Mozilla/5.0 (X11; Linux x64) AppleWebKit/537.36 (KHTML, like Gecko) HappyDOM/0.0.0 is an User-Agent not JA4 digest, so you need to set the Rule accordingly
I had a JA4 Digest rule earlier but removed it after your clarification.
I haven’t re-added the User-Agent rule yet, because when I previously tried blocking by HappyDOM in the User-Agent string, the requests were still marked as Allowed.
It’s been two days since I added a User-Agent blocking rule, but I’m still seeing requests with the HappyDOM user-agent marked as Allowed in the Firewall logs.
The issue seems to be resolved for now — I haven’t seen any new HappyDOM requests.
The deny rule I set up ended up blocking some internal Vercel services like vercel-favicon/1.0, which was unexpected.
I’m going to remove that rule to avoid affecting Vercel’s own traffic and will keep monitoring.
I really don’t know how it’s possible, but I see HappyDOM requests in the Firewall logs again.
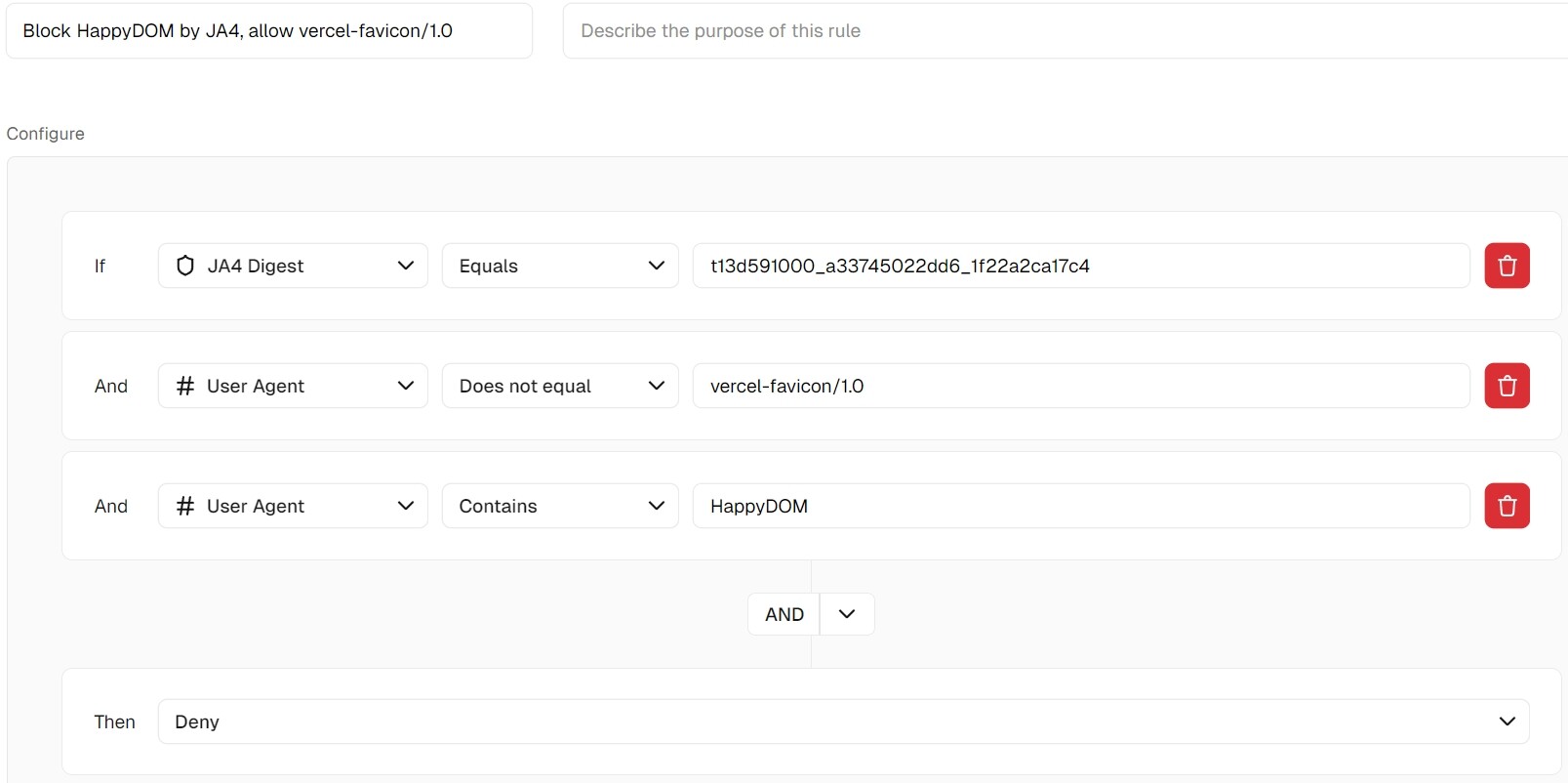
I created a rule specifically to block HappyDOM via JA4 Digest, while making sure to exclude vercel-favicon/1.0, since they both (for some reason) share the exact same JA4 fingerprint.
Previously, when I blocked this JA4 directly (t13d591000_a33745022dd6_1f22a2ca17c4), it ended up blocking vercel-favicon/1.0 as well — which I didn’t want. So I adjusted the rule to look like this:
IF
JA4 Digest == t13d591000_a33745022dd6_1f22a2ca17c4
AND
User-Agent != vercel-favicon/1.0
AND
User-Agent CONTAINS HappyDOM
THEN
Deny
It seemed to work at first, but now I’m seeing HappyDOM requests with that same JA4 Digest showing up again in the logs.
Not sure if the rule isn’t being applied correctly, or if something else is going on.
I’ll attach screenshots of the rule and the recent requests from HappyDOM.
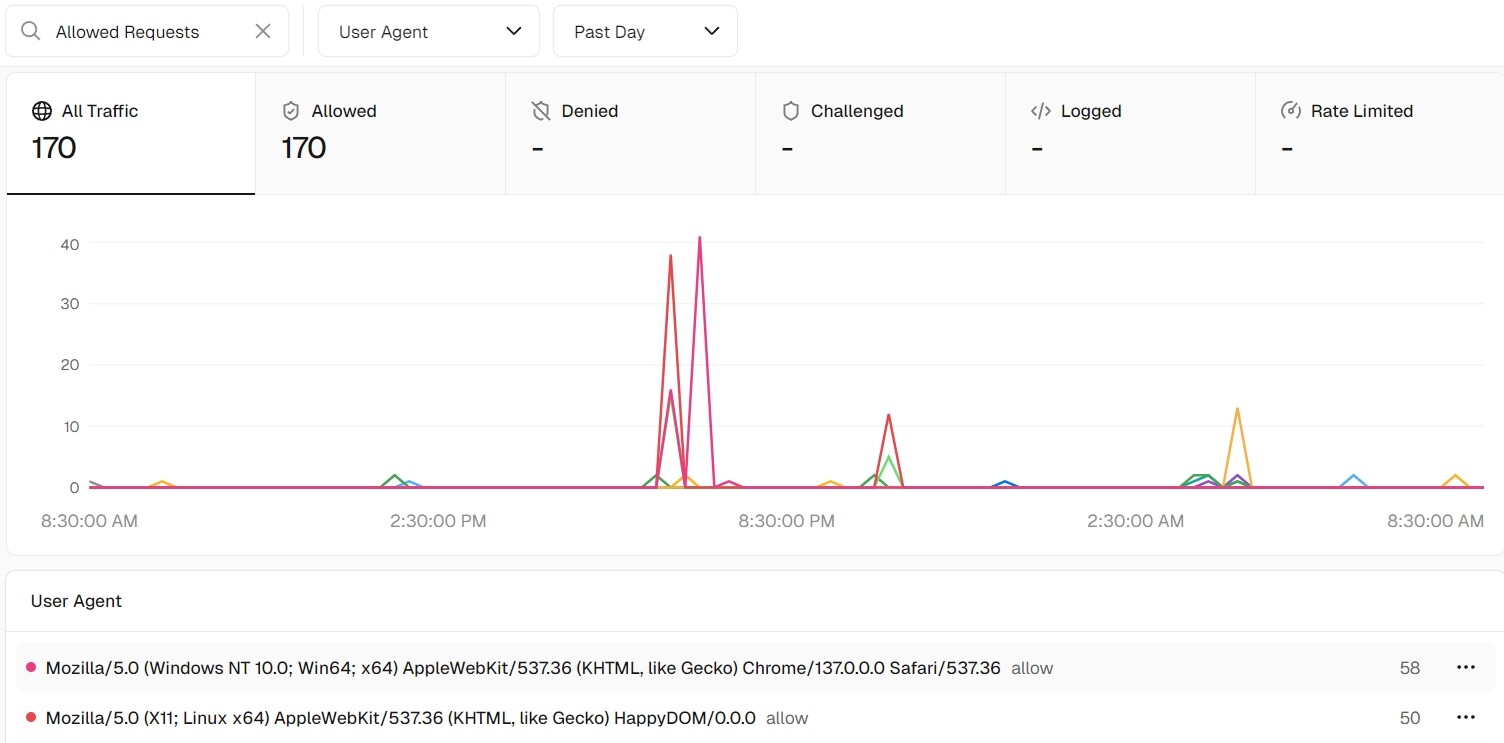
Over the past few days, I’ve noticed something about HappyDOM. It consistently appears in the Firewall Allowed Requests at the exact same time as vercel-favicon/1.0.
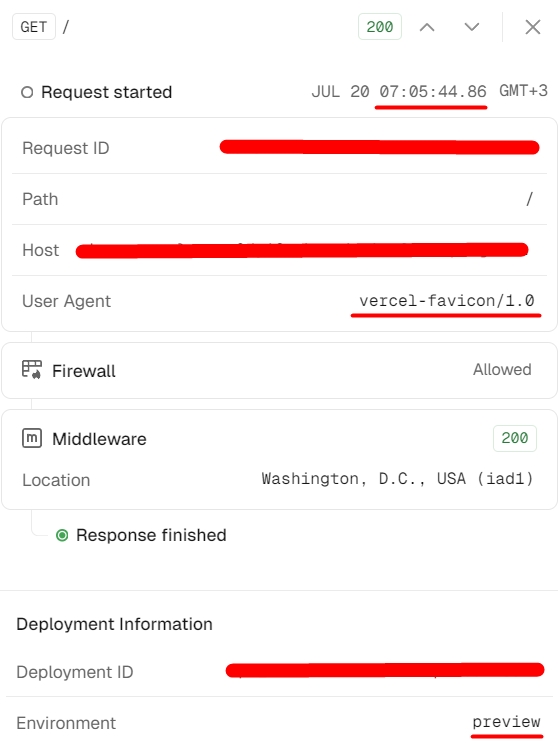
Today, I observed a similar pattern again: a request from vercel-favicon/1.0 appeared in the logs for a preview branch, and right at the same moment, a HappyDOM request was logged in the firewall (as seen in the first screenshot above).
However, I haven’t been able to find any trace of HappyDOM in the Logs tab or anywhere else (only in the Firewall section), even though I have a rule to log a User Agent which contains HappyDOM.
Plus, I had a logging rule for the JA4t13d591000_a33745022dd6_1f22a2ca17c4, which apparently belongs to HappyDOM, but instead I was seeing vercel-favicon/1.0 in the logs.
This made me wonder - could HappyDOM be an internal service used by Vercel for preview deployments? My assumption is that preview branches aren’t accessible externally, so any HappyDOM traffic must be internal (I hope so ).
That might also explain why I haven’t been able to detect HappyDOM via custom middleware or standard logs - because it’s handled internally.
Can someone from the team confirm whether HappyDOM is indeed part of Vercel’s infrastructure?