There are currently 3 different models available on v0
- v0-1.5-sm ($0.50 / million tokens)
- v0-1.5-md ($1.50 / million tokens)
- v0-1.5-lg ($7.50 / million tokens)
These aren’t real models in the conventional sense, but instead are composite models that combine base models with refinements to improve code quality output
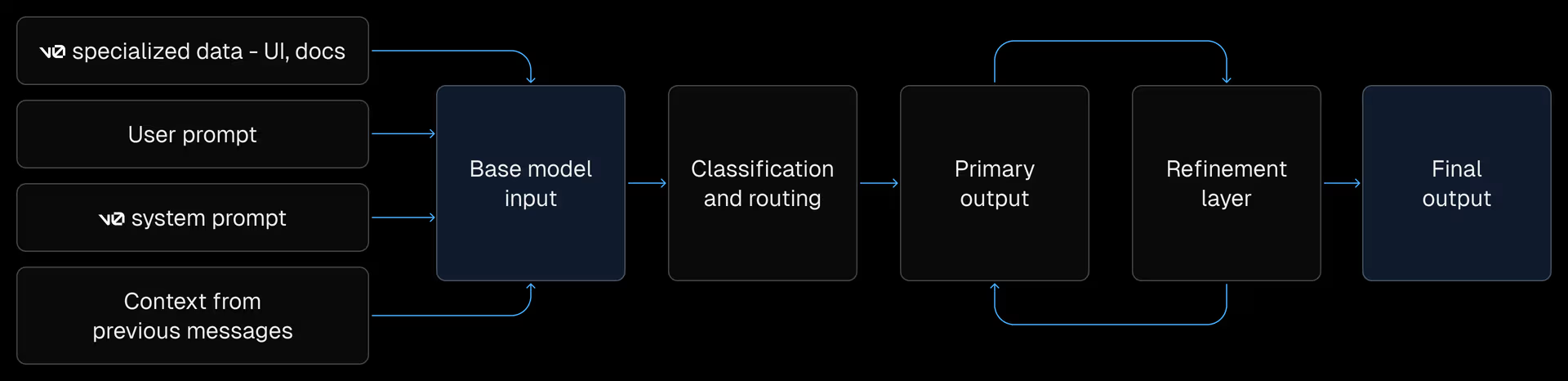
small model
Use the small model for edits and Q&A
All three of the models get the same specialized data which means the small model is just as good at answering general technical questions as the others. It does have a smaller context window though, so questions about larger codebases or complex topics may start to hallucinate.
In my experience the small model is pretty good at editing code and less good at writing new code. In our evaluations, the small model has a much higher error rate than the medium model for code, however it is 3x cheaper so you can afford to try a couple times
If you are cost-sensitive, use the small model more often but be ready to drop into the code for fixing syntax errors and incorrect imports. You can highlight code with CMD+K and do targeted prompts to make specific changes while minimizing token usage.
Typical small prompts
- use outline buttons instead of primary
- make the header card more minimal
- remove useEffect and derive state in render
- use a single column layout on mobile
medium model
Use the medium model for most prompts
The medium model scores the highest on our evals for code quality, which means it will write proper code, valid imports, not hallucinate module names, and so on more often than any of the other models.
Typical medium prompts
- create a user profile page
- add a list of comments to the profile page
- make the homepage dark mode friendly
- add a contact form at /contact that writes to the DB
- give administrators a page where they can see all pending contact submissions and mark them as done
large model
Use the large model for debugging, planning, reasoning across multiple files, and complex theoretical logic
The large model has the biggest context window, so it’s capable of understanding much more about your codebase or any other documentation you give it
As it’s a larger model it knows much more but is also prone to small physical mistakes, which makes it less suitable for coding than the medium model.
Typical large prompts
- without writing any code, how should we set up a permissions system that allows administrators to add and remove permissions from other users?
- there’s a bug where data is not loading on the dashboard. Check
dashboard.tsx,api/data.ts, andlib/utils.tsfor potential culprits and suggest a debugging approach - based on my current implementation and product requirements, redesign my DB schema for max performance at around 1000 active users a day
other notes
- the Fix in v0 button will pick a model for you regardless of what you have selected. This will never be the large model
- some tasks aren’t great fits for AI models, like renaming a variable everywhere in the codebase. This will use a lot of tokens and is much faster to do in a real IDE and git sync back into v0
How have you all been using the different models? Have you found any patterns that seem helpful?