Hi Team, I have read through forum and I see lots of similar issues are already reported on forum. These repetitive, meaningless tokens still count toward thousands of “consumed” AI tokens
It will be useful to see from team is :
- Quality‐gate before counting usage : Only charge tokens for suggestions that pass a minimal “sanity check” (e.g. no more than X repeated substrings, or valid TypeScript syntax).
- Usage only upon acceptance : Defer billing until the user actually applies or approves an AI suggestion in their code.
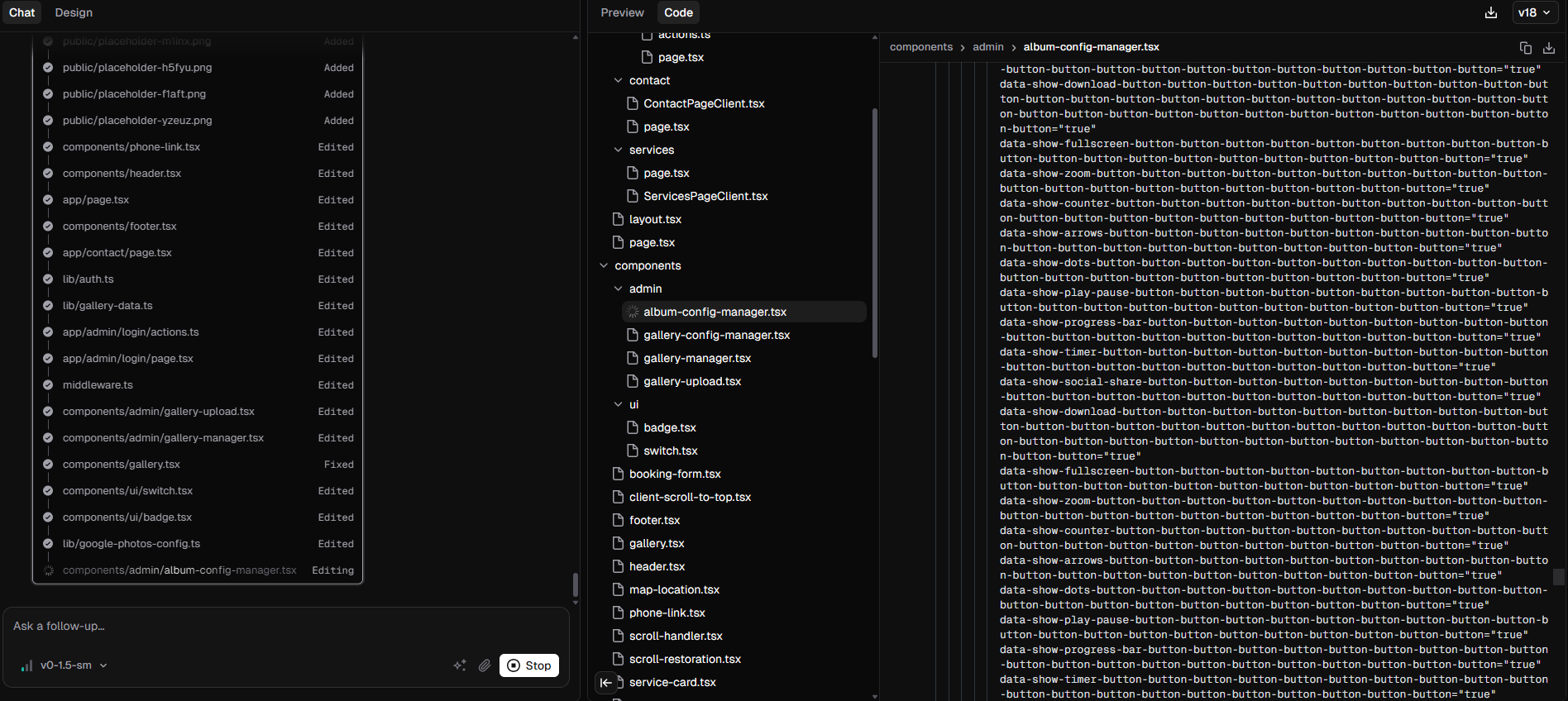
Also another observation is that :
When I start a project using the md model and later switch to sm for a few queries, my completions degenerate and sometimes outright break existing code.
Why it matters
I expect a smooth fallback—if I downgrade temporarily, it shouldn’t orphan all my previous context. Switching models mid-project can cost time chasing phantom bugs.
Without a warning or compatibility note, I assumed “all v0 models share the same context” and was surprised by the breakage.
Suggested improvements
Model-switch warning: Prompt the user “Switching models will reset your existing context—continue?”
Cross-model context migration: Automatically re-tokenize/re-embed your project history so switching is seamless.
Documentation: Clearly call out in the README or dashboard how sm|md|lg differ in tokenization and context handling.
Note : I used AI to prepare this and share as constructive feedback