I’ve been using v0 for a while now and I originally chose it because the UI designs were clean, premium, and way better than anything other AI builders could produce. That was the main reason I picked v0 over other tools.
But now, after the change from the old monthly subscription to this new usage-based model with tokens, I feel like the design quality dropped hard. No matter how I write the prompts, the results are super generic, low quality, and honestly unusable for serious projects. It feels like the AI just throws random blocks on the page without any taste or structure.
I’m saying this with full respect, because I really liked v0 and I still want to use it, but something’s definitely off lately. It’s not just a small drop it’s a massive downgrade in what used to be the strongest feature of the platform.
If anyone else feels the same, reply or react to this message so maybe the team can hear us and bring back what made v0 special in the first place.
This is honest feedback from someone who believed in this tool and still wants it to succeed.
Appreciate you reaching out to share your experience. Do you have any specific examples I can share with the team?
There’s not much detail to go on here. It would be really helpful to see some examples of your prompts and the output you didn’t like. Otherwise, we can’t be sure what should be changed
Thanks for the response. I understand the need for more context, so here’s a bit more detail.
I’ve built two custom GPTs specifically to work with v0. One is focused on UI design, and the other on development structure. I’ve studied how v0 works and crafted my prompts based on that. These GPTs generate highly tailored instructions meant to get the best out of the system.
Even with all of that, the output has become consistently generic. The sections feel disconnected, the components look like basic UI kits, and there’s barely any animation or structure. It’s just stacked blocks with placeholder text and colored backgrounds. Even when I reference modern design, strong brands, and ask for high-level creative layout, the results still fall flat.
When I first started using v0, the designs had more depth. There were better font choices, spacing, animations, and a clear sense of structure. Now that feeling is gone. I noticed the shift around the same time the pricing moved from a monthly subscription to the new usage-based token model. I’m not saying it’s directly related, but that’s when the drop became noticeable.
That said, I don’t want to just blame the tool. Maybe there’s something I’m missing. Maybe there’s a new way of structuring prompts or designing workflows that your team knows and we don’t. If you’re part of the team or close to it, I’d really appreciate it if you could share how we can structure the best possible UI outputs using v0 right now. If there’s a better method than using custom GPTs, I’m open to learning it.
At the end of the day, we just want to create great results. So if you have insight, we’re listening.
rather than relying on examples from users, why not try running prompts yourself and see what the GPT delivers? I’ve had so many experiences of the GPT failing to follow instructions and I even had it state that it did so because it was being lazy…still took money from my tokens.
I’m sure like my fellow users, I don’t really have the time to supply Vercel with specific examples, but I think you can surmise from the numerous forum posts on this that it exists and is a real issue. I’ve had a month break from V0 and this still has not been resolved.
Useful feedback @animerezz-1240! Thank you for sharing that. I’ll hand it over to the team to help guide future iterations.
There’s some great tips in the community handbook if you want to learn more about prompting strategies. I think the topics on theming, design mode, and strategic forking would be useful for you.
@brianmrobinson50-733 We use v0 every day at Vercel. Dogfooding is very much part of the culture here.
When we ask for examples, it’s because “it’s not good” doesn’t give us enough detail to know what should be changed. Imagine going to a doctor, telling them “I feel unwell”, and expecting them to be able to fix you with no other details. In the absence of actual telepathy, of course, we need to ask for more information.
Remember that every message you send in a chat teaches the AI to respond in a way that it expects you want. If you call it stupid and tell it that it’s lazy, then the responses you get will start to match that expectation. The community handbook topics about v0 linked above can help you learn how to get LLMs to give the output you want.
thanks for the reply, it is much appreciated. I also appreciate what you are saying, but if I was a doctor and I had 100 unconscious patients, I would run all sorts of tests to see if I can identify/triage the root cause of the problem and not rely on accompanying evidence. There is obviously an issue, as I have 100 unconcious patients! In the same way, there are numerous complaints on these forums that payment is taken despite the GPT failing to actually carry out the prompt.
I always follow the advice in the community handbook and work with LLM’s at my place of work…I run my prompts via ChatGPT before inputting to V0, yet it often takes a payment but doesn’t apply any meaningful changes to the code.
Personally I think v0 performed very well just before the transition into .app and the agent approach.
The ability to choose model, and even better, the gpt 5, usually performed well and according to what I wanted. The new implementation creates worse results and takes longer.
I think one potential cause is that the agent aims to do “too much” before confering me. I also used to leverage the heavier models for complex tasks (lg and gpt 5) and I did experience huge differences on those. Now it seems to use md for everything.
Amy, is this just issues “right now” due to not having had the new version fully tested? I miss the version of v0 a few weeks back!
I’m having pretty insane issues with v0 now too where it can’t even complete simple tasks that it used to cut through with ease. Right now, I’m experiencing the model getting stuck in infinite loops where it refuses to make any code changes even after I repeatedly point out that nothing has been written. It then gets mad at itself and infinite loops again telling itself to read the existing code before trying to write new code again.
I tried opening a new chat, changed my prompts, and still it’s getting stuck in a loop. Now it’s a loop of not updating the code and it trying to create a page.tsx.
What happened to v0? It was the best AI model I used a few weeks back and now it’s unusable.
the quality is definitely down. The output provided has nothing to do with the actual implementation.
Some common issues i’ve had is classical stopping of execution. Basically resisting executing really simple commands like (increase font size for a section) which typically it does with no issue.
I’ve also had a few times complete design rehauls when prompting it specifically and clearly not to update anything as i’m just brushing up before production.
I would venture to even boldly claim that the full redesign always happen when asked for only simple updates.
When prompted to explain and show what’s done, it puts together an imaginary list of actions and goes ahead to rewire API calls and mess up the entire connection. This then causes run-time errors which it fixes by removing entire elements in the app. Really wild and highly unpredictable. It’s scary…
I completely agree with this. For me it’s not just that the UI quality has dropped — it honestly feels like the whole system is now engineered to burn credits without delivering anything useful.
A few months ago, spending $20–30 a month gave me results that were at least workable. Yesterday I burned through $40 in a single day and got nothing but garbage. Most instructions are ignored, and worse, the ones that are supposed to optimize costs and reduce pointless “work” are blatantly disregarded.
Just today, the model needed 10 iterations to (still unsuccessfully) change button text color to white. $10–12 wasted on a single, trivial task. That’s ridiculous.
And when I tried to request a refund through the official form, the moment you select the invoice the Submit button is conveniently greyed out. Pure coincidence, I guess.
I’m preparing to file a chargeback because I genuinely don’t believe the service is being delivered properly. Honestly, I think more people should consider doing the same. Only real financial pressure will ever push them toward customer-friendly changes.
V0 doesn’t care about its users anymore, only about its own profit just like every other company.
At the beginning it was cheap to attract customers, but then they showed their real face. What used to cost 0.02 or 0.05 now costs 0.20 as if nothing. The community team always gives the same copy-paste answers and nothing ever changes.
They only added the -sm mode after the whole mess about high prices and limited usage just to calm people down. Now they launch this agent mode that charges whatever it wants, whenever it wants, however it wants.
And the HR response? “We’ll forward it to the team” bla bla bla, just lies. If we can’t even trust the few people who are supposed to listen to us, what’s left? Look for other options because trust is gone.
Before agent mode, $30 gave you more than 100 prompts, now you’re lucky if you even reach 100. The reality is clear: prices keep rising, while users get less and less.
Very much the case, it used to produce top notch UI. Especially if you asked it to use ShadCN, after Agent was introduced quality went significantly down. Buttons are no aligned, quite strange page architecture, tables that don’t make any sense, coloring that is just awful. Not sure what they’ve done, but it’s not good. Their evals might be good on paper but practically it’s pretty bad.
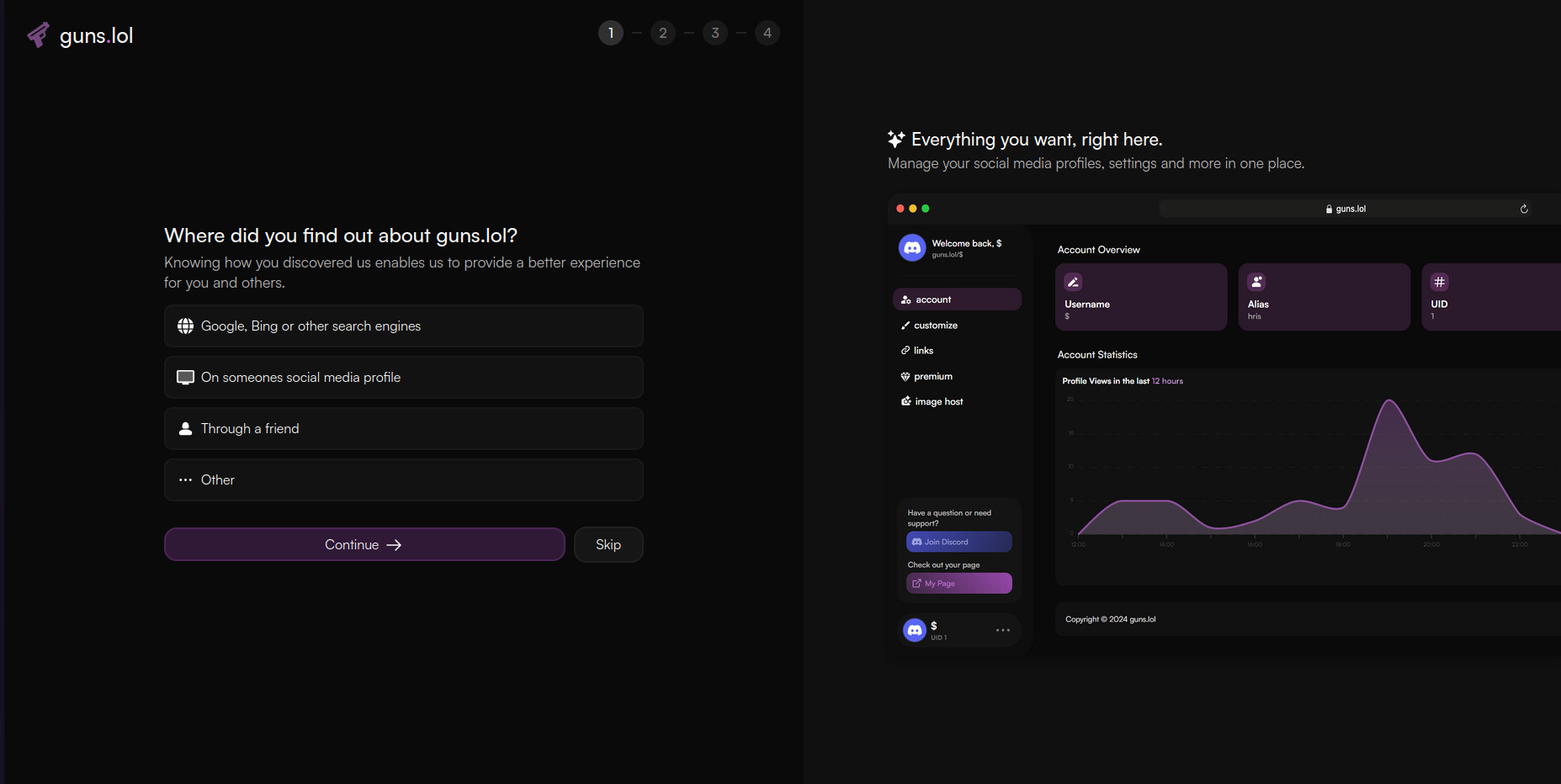
@amyegan here’s good example pictures attached. I’ve been a paid customer of v0 since April and I remember how I could consistently send v0 Mockup images and v0 would make an exact replica in ShadCN/Tailwind code. Then in June-July I believe this ability to generate a UI that at all resembled the screenshot sent in diminished. Even when I used the expensive large model instead of medium, it failed to make anything similar. Despite the fact that just 2-3 days before, even medium model could reliably clone screenshots.
Takeaway TLDR: You & other vercel employees probably don’t try to clone UI design screenshots much in your daily dogfooding of the product. I think any user who often clones screenshots with v0 will attest the quality randomly decreased dramatically one morning around the time of June-July. And these screenshotted sites are often using ShadCN and Tailwind & v0 still fails to generate a design at all similar in style to the pictures.
My pictures are attached below. This is an expensive UI and it’s value to me was that it could previously design better than other AIs. if the model doesn’t get smoothed out soon I’m going to cancel my subscription.
This is disappointing, the pictures look nothing like the reference picture and the steps 1-2-3-4 in the 2nd output are aligned to the right end of the page, when in my reference picture it’s super clear it’s in the middle of the page.
The prompts I’ve been feeding v0 are no less descriptive than before when v0 worked. In fact, I clicked v0’s button to clone a screenshot and it still looks this disappointing. I try explicitly mentioning Tailwind CSS because that’s what the reference site uses, no luck there either.
I’m getting better results when I use other AI companies that don’t advertise themselves as design AIs. This quality change was instant overnight and I expected it was probably just a tuning update Vercel would soon revert or train to be corrected. Yet we’re now more than 2 months later and the quality is just as poor as that day the model worsened.